
Rabbit's web-based 'large action model' agent arrives on r1 as early as this week
The Rabbit r1 was the must-have gadget of early 2024, but the blush fell off it pretty quick when the company's expansive promises failed to materialize. CEO Jesse Lyu admits that "on day one, we set our expectations too high" but also said that an update coming to devices this month will finally set the vaunted Large Action Model free on the web.
While skeptics may (justifiably) see this as too little, too late, or another shifting of goalposts, Rabbit's aspiration of building a platform-agnostic agent for web and mobile apps still has fundamental — if still largely theoretical — value.
Speaking to TechCrunch, Lyu said that the last six months have been a whirlwind of shipping, bug fixes, improving response times, and adding minor features. But despite 16 over-the-air updates to the r1, it remains fundamentally limited to interacting with an LLM or accessing one of seven specific services, like Uber and Spotify.
"That was the first-ever version of the LAM, trained on recordings collected from data laborers, but it isn't generic — it only connects to those services," he said. Whether or not it was what they call the LAM is pretty much academic at this point; whatever the model was, it didn't provide the capabilities Rabbit detailed at its debut.

A generalist web-based agent
But Rabbit is ready to release the first generic version, which is to say not specific to any app or interface, of the LAM, which Lyu demonstrated for me.
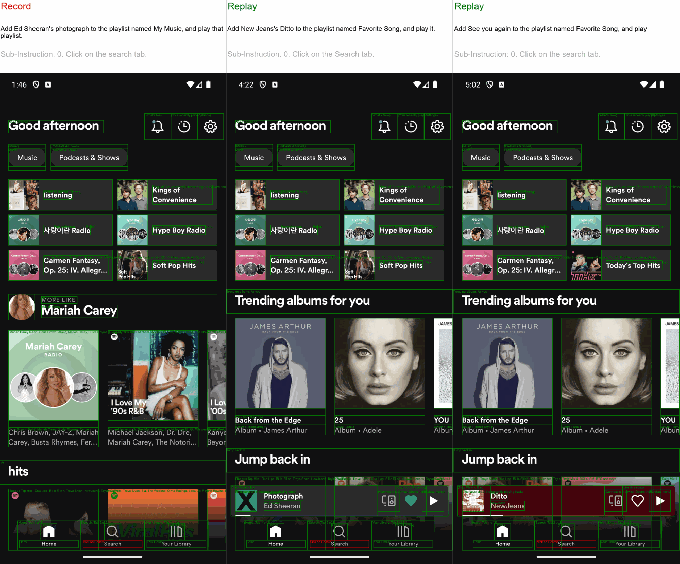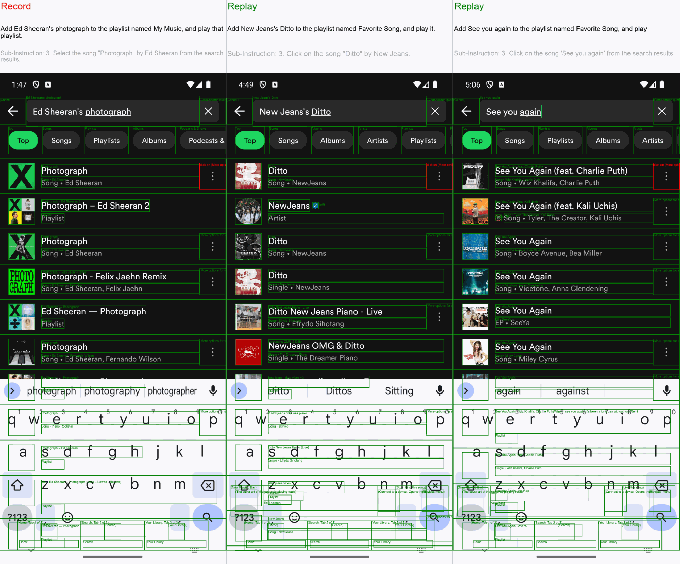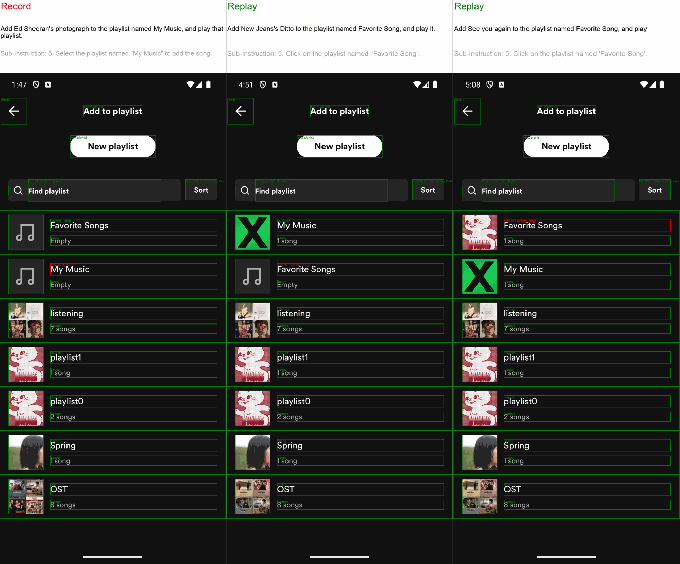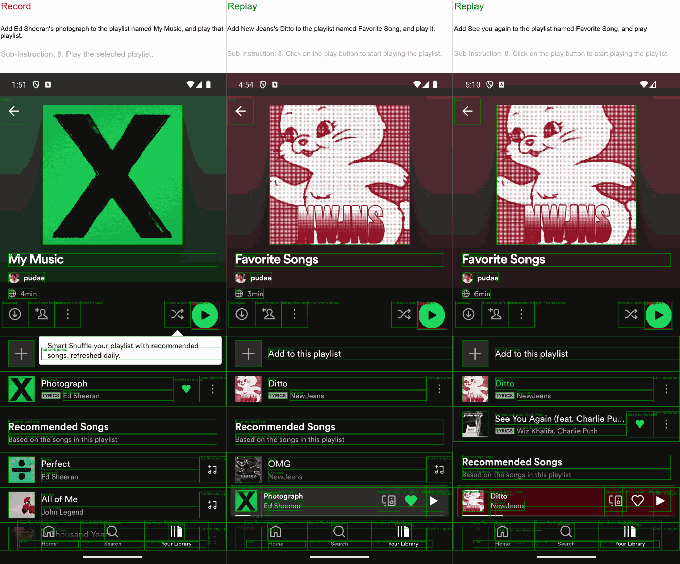
This version is a web-based agent that reasons out the steps to do any ordinary task, like buying tickets to a concert, registering a website, or even playing an online game. "Our goal is very clear: At the end of September, your r1 will suddenly do lots more things. It should support anything you can do on any website," Lyu said.
Given a task, it first breaks that task down into steps, then starts executing them by analyzing what it sees on screen: buttons, fields, images, regardless of position or appearance. Then it interacts with the appropriate element based on what it has learned in general about how websites work.
I asked it (through Lyu, who was operating it remotely) to register a new website for a film festival. Taking an action every few seconds, it searched for domain registries on Google, picked one (a sponsored one, I think), put film festival in the domain box, and from the resulting list of options picked "filmfestival2023.com" for $14. Technically I hadn't given it any constraints like "for 2025" or "horror festival" or anything.
Similarly, when Lyu asked it to search for and buy an r1, it quickly found its way to eBay, where dozens were on sale. Perhaps a good result for a user but not for the founder of the company presenting to the press! He laughed it off and did the prompt again with the addition that it should buy only from the official website. The agent succeeded.
Next, he had it play Dictionary.com's daily word game. It took a bit of prompt engineering (the model found an out in that it could quickly finish by hitting "end game") but it did it.
Which browser does it use, though? A fresh, clean one in the cloud, Lyu said, but they are working on local versions, like a Chrome extension, that would mean you can use existing sessions and it wouldn't have to log into your services.
To that end, as users are understandably (and rightly) wary of giving any company full access to their credentials, the agent is not equipped with those. Lyu suggested that a walled-off small language model with your credentials could be privately invoked in the future to perform logins. It seems to be an open question how this will work, which is somewhat to be expected given the newness of the space.
Still learning
The demo showed me a couple things. First, if we give the company and its developers the benefit of the doubt that this isn't all some elaborate hoax (as some believe), it does appear to be a working, general-purpose web agent. And that would be, if not a first in itself, certainly the first to be easily accessible to consumers.
"There are companies doing verticals, for Excel or legal documents, but I believe this is one of the first general agents for consumers," Lyu said. "The idea is you can say anything that can be achieved through a website. We'll have the generic agent for websites first, then for apps."
Second, it showed that prompt engineering is still very much needed. How you phrase a request can easily be the difference between success and failure, and that's probably not something ordinary consumers will tolerate.
Lyu cautioned that this is a "playground version," not final by any means, and that although it is a fully functioning general web agent, it still can be improved in many ways. For instance, he said, "the model is smart enough to do the planning, but isn't smart enough to skip steps." It wouldn't "learn" that a user prefers not to buy their electronics on eBay, or that it should scroll down after searching to avoid the wall of sponsored results.
User data won't be harvested to improve the model — yet. Lyu attributed this to the fact that there's basically no evaluation method for a system like this, so it is difficult to say quantitatively whether improvements have been made. A "teach mode" is also coming, though, so you can show it how to do a specific type of task.
Interestingly, the company is also working on a desktop agent that can interact with apps like word processors, music players, and of course browsers. This is still in the early stages, but it's working. "You don't even need to input a destination, it just tries to use the computer. As long as there is an interface, it can control it."
Third, there is still no "killer app," or at least no obvious one. The agent is impressive, but I personally would have little use for it, being unfortunately sitting in front of a browser for 8 hours a day anyway. There are almost certainly some great applications, but none sprang to mind that makes the utility of a browser-based automaton as obvious as that of, say, a robot vacuum.
Why not an app, again?
I raised the common objection to the entire Rabbit business model, essentially that "this could be an app."
Lyu has clearly heard this criticism many times, and he was confident of his answer.
"If you do the math, it doesn't make sense," he said. "Yes, it's technically achievable, but you're going to piss off Apple and Google from day one. They will never let this be better than Siri or Gemini. Just like there's no way Apple intelligence is going to control Google stuff better, or vice versa. And they take 30% of revenue! If at the beginning we'd just built an app, we'd never have this momentum."

The fundamental pitch Rabbit is making is that there can be a third-party AI or device that can access and operate all your other services, and from outside them, like you are. "A cross-platform, generic agent system," as Lyu called it. "We'll control every UI, and the website is a good start. Then we'll go to Windows, to MacOS, to phones."
Speaking of which: "We never said we'd never build a phone in the future." Isn't that antithetical to their original thesis of a smaller, simpler device? Maybe, maybe not.
In the meantime, they're working on starting to fulfill the promises they made early this year. The new model should be available to any r1 owner sometime this week when the OTA update goes out. Instructions on how to invoke it will arrive then as well. Lyu cautioned expectant users with his characteristic understatement.
"We're setting the expectations right. It's not perfect," he said. "It's just the best the human race has achieved so far."

